Layer 4 vs Layer 7 proxy
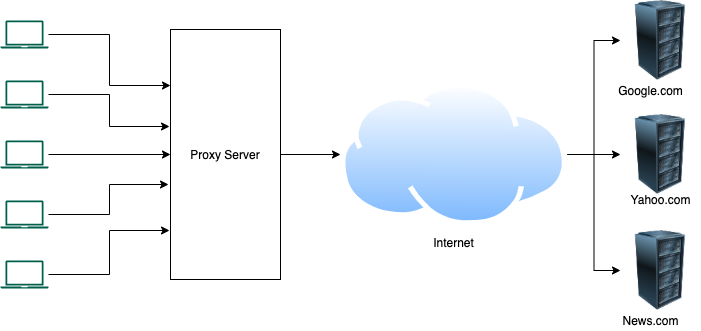
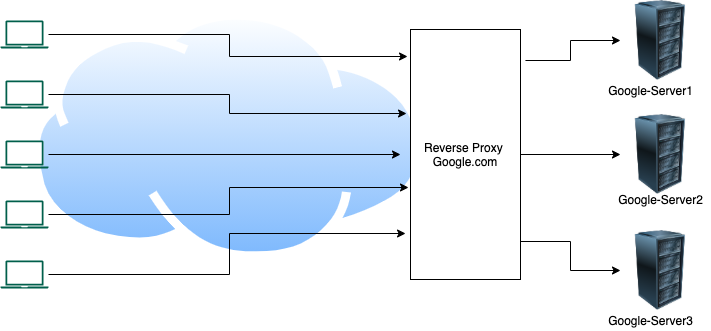
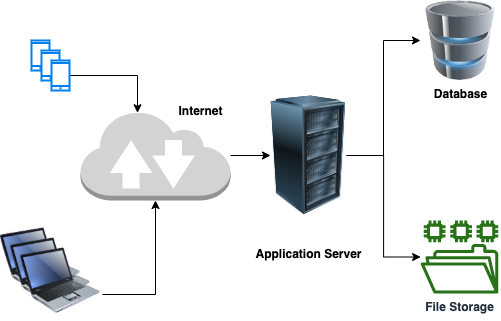
In the last couple of posts, we talked about what is a reverse proxy and how to implement it using Envoy proxy. In this post, we will understand how a layer 4 proxy is different from a layer 7 proxy, and deploy these using Envoy proxy.
Before jumping into the difference between layer 4 and layer 7 proxy, it makes sense to revisit the OSI model or open system interconnection model. OSI model helps us visualize networking communication as 7 layered representation, where each layer adds functionality on top of the previous layer.
For OSI Model Refer
https://en.wikipedia.org/wiki/OSI_model
https://medium.com/software-engineering-roundup/the-osi-model-87e5adf35e10
Focusing on layer 4 and layer 7, we understand a very important difference. At layer 7, we have a complete request coming in from the client i.e. we understand what the actual request is? is it a GET request or a POST request? is the end-user asking for /employee or /department? whereas at layer 4 all we are looking at is data packets in raw format, hence there is no way for us to know what resource is being requested for.
Layer 7 implementation makes sure that the proxy receives all the incoming packets for a request, recreates the request, and makes a call to the backend server. This helps us implement certain features like TLS offloading, data validation, rate limiting on specific APIs, etc. On the other hand, for Layer 4 proxy, all we are doing is passing on the packets being received to the backend server. The advantage here is that it is fast (no data processing) and can be considered secured (again we are not looking into data). Based on application need one can choose either layer 7 or layer 4 proxying.
A good explanation on layer 4 vs layer 7 proxy
It makes sense now to pick up from where we left Envoy proxy implementation in the last post. We used envoy.filters.network.http_connection_manager which helps us implement layer 7 reverse proxy. To extend the example, we will add one more hello world implementation.
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 127.0.0.1, port_value: 8080 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: local_service
domains: ["*"]
routes:
- match: { prefix: "/" }
route: { cluster: some_service }
http_filters:
- name: envoy.filters.http.router
clusters:
- name: some_service
connect_timeout: 1s
type: STATIC
lb_policy: round_robin
load_assignment:
cluster_name: some_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 1111
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 2222You can see we have added another localhost application server running at port 2222. For sake of differentiating we have made these 2 applications return “Hello world 1111” and “Hello world 2222”. Now when we hit localhost:8080 for envoy proxy, we can see we are getting both the results alternatively.
$ curl localhost:8080
Hello World 1111
$ curl localhost:8080
Hello World 2222
To convert the existing Envoy proxy config YAML to support layer 4 routing, we just need to change the name and type of filter to envoy.filters.network.tcp_proxy
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 127.0.0.1, port_value: 8080 }
filter_chains:
- filters:
- name: envoy.filters.network.tcp_proxy
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.tcp_proxy.v2.TcpProxy
stat_prefix: ingress_http
cluster: some_service
clusters:
- name: some_service
connect_timeout: 1s
type: STATIC
lb_policy: round_robin
load_assignment:
cluster_name: some_service
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 1111
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 2222You can see the YAML looks simpler as we cannot support path-based routing in layer 4 reverse proxy. The results remain the same as hitting localhost:8080 will still hit backend servers running at 1111 or 2222, but as explained above, the mechanism being used behind the scenes has changed.