Sometime back I talked about the importance of containers in implementing Microservices-based applications. Implementing such a design comes up with its own challenges, that is, once the number of services and containers grows, it becomes difficult to manage so many container deployments, scaling, disaster recovery, availability, etc.
Container Orchestration with Kubernetes
Because of the challenges mentioned above with container-based deployment of Microservices, there is a strong need for container orchestration. There are a few Container orchestration tools available but it will not be wrong to say that Kubernetes is the most popular at this point of time.
Kubernetes or K8s as it is popularly knows, provides following features off the shelf
- High availability – no downtime
- Scalability – high performance
- Disaster Recovery – backup and restore
Kubernetes Architecture
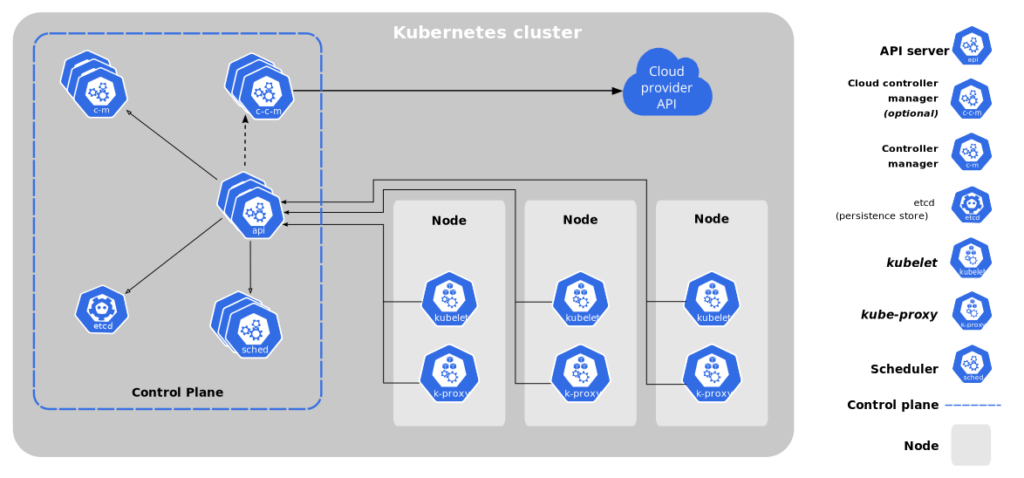
Let us take a look at how K8s achieves the features we mentioned above. At the base level, K8s nodes are divided into Master node and Worker nodes. The master node, as the name suggests is the controlling node that manages and controls the worker nodes. Master node makes sure services are available and scaled properly.
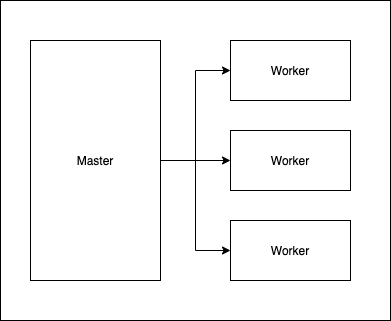
Master Node
Master node contains contains following components- API server, Scheduler, Controller and etcd.
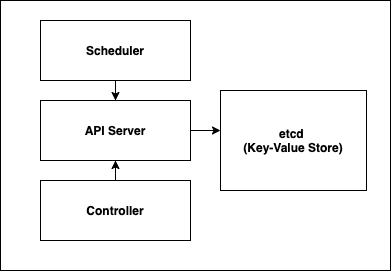
API server: The API server exposes APIs for various operations to external users. It validates any request coming in and processes it. API can be exposed through REST calls or a command-line interface. The most popular command-line tool to access API is KubeCTL.
Scheduler: When a new pod (we will look into pods shortly when discussing worker nodes) is being created, the scheduler checks and deploys the pod on available nodes based on configuration settings like hardware and software needs.
Controller/ Control Management: As per official K8s documentation, there are four types of controllers that manage the following responsibilities.
- Node controller: Responsible for noticing and responding when nodes go down.
- Replication controller: Responsible for maintaining the correct number of pods for every replication controller object in the system.
- Endpoints controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token controllers: Create default accounts and API access tokens for new namespaces.
etcd: The etcd is a key-value database store. It stores cluster state at any point in time.
Worker Node
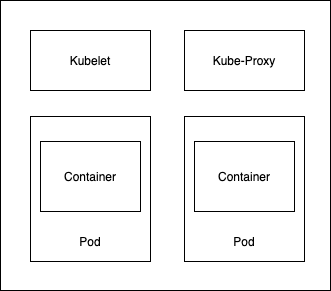
kubelet: It runs on each node and makes sure all the containers running in pods are in healthy state and takes any corrective actions if required.
kube-proxy: It maintains network rules on nodes. These network rules allow network communication to your Pods from network sessions inside or outside of your cluster.
Pods and Containers: One can think of a Pod as a wrapper layer on top of containers. Kubernetes does not want to work directly with containers to give it flexibility so that the underlying layer does not have any dependency.