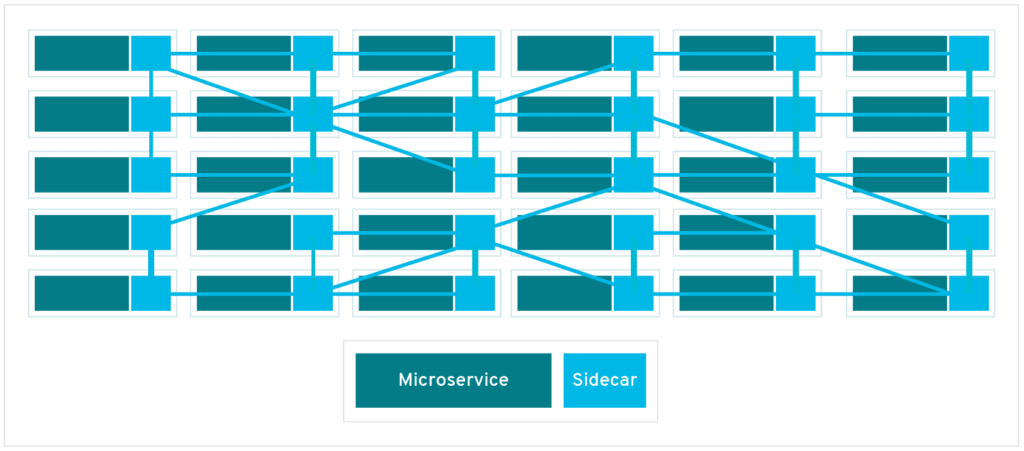
Before getting into service Mesh, let’s try to understand what a Sidecar pattern is?
Sidecar Pattern
When we develop an application that has multiple Microservices talking to each other, it can bring along a lot of complexities. For example, a service needs to implement features like logging, rate-limiting, retry logic, circuit breaker, timeouts, and so on. These features are needed for making sure the service is able to connect to other services and other services can connect to this. But if we look closely, all these features do not add value directly to the business logic implemented by the service and can be considered as an additional burden on the core functionality.
Sidecar
Service Mesh
We just saw how a sidecar can help a Microservice to offload unnecessary complexity outside of the code service. Now think of a scenario where we have multiple services communicate with each other. All services can offload the boilerplate code to sidecars.
A service mesh helps to manage sidecars for all Microservices in a central manner. It helps controls the deployment, configurations, updates of sidecars in a central manner.
In the last couple of posts, we talked about what is a reverse proxy and how to implement it using Envoy proxy. In this post, we will understand how a layer 4 proxy is different from a layer 7 proxy, and deploy these using Envoy proxy.
Before jumping into the difference between layer 4 and layer 7 proxy, it makes sense to revisit the OSI model or open system interconnection model. OSI model helps us visualize networking communication as 7 layered representation, where each layer adds functionality on top of the previous layer.
Focusing on layer 4 and layer 7, we understand a very important difference. At layer 7, we have a complete request coming in from the client i.e. we understand what the actual request is? is it a GET request or a POST request? is the end-user asking for /employee or /department? whereas at layer 4 all we are looking at is data packets in raw format, hence there is no way for us to know what resource is being requested for.
Layer 7 implementation makes sure that the proxy receives all the incoming packets for a request, recreates the request, and makes a call to the backend server. This helps us implement certain features like TLS offloading, data validation, rate limiting on specific APIs, etc. On the other hand, for Layer 4 proxy, all we are doing is passing on the packets being received to the backend server. The advantage here is that it is fast (no data processing) and can be considered secured (again we are not looking into data). Based on application need one can choose either layer 7 or layer 4 proxying.
A good explanation on layer 4 vs layer 7 proxy
It makes sense now to pick up from where we left Envoy proxy implementation in the last post. We used envoy.filters.network.http_connection_manager which helps us implement layer 7 reverse proxy. To extend the example, we will add one more hello world implementation.
You can see we have added another localhost application server running at port 2222. For sake of differentiating we have made these 2 applications return “Hello world 1111” and “Hello world 2222”. Now when we hit localhost:8080 for envoy proxy, we can see we are getting both the results alternatively.
$ curl localhost:8080
Hello World 1111
$ curl localhost:8080
Hello World 2222
To convert the existing Envoy proxy config YAML to support layer 4 routing, we just need to change the name and type of filter to envoy.filters.network.tcp_proxy
You can see the YAML looks simpler as we cannot support path-based routing in layer 4 reverse proxy. The results remain the same as hitting localhost:8080 will still hit backend servers running at 1111 or 2222, but as explained above, the mechanism being used behind the scenes has changed.
In the last post, I talked about proxy servers and how they are an integral part of the cloud and microservices-based design. It makes sense to get our hands dirty and try out setting a reverse proxy. I have chosen the Envoy proxy for this example.
Envoy proxy can be installed on most of the popular OS and also has a docker installation. The site gives very good documentation for getting started –https://www.envoyproxy.io/docs/envoy/latest/start/start. For this example, I am setting up an envoy proxy on Mac OS.
First of all, make sure you have brew installed. Then execute the following commands to install envoy proxy
brew tap tetratelabs/getenvoy
brew install envoy
Finally, check the installation: envoy --version
Once we are satisfied with the overall installation, we can run a simple test case, where we will redirect traffic coming to the envoy proxy to an application server. To start with, I have deployed a simple hello world application on port 1111.
A couple of things to observe in the above YAML file, first observe the filter we are using here. We are using envoy.filters.network.http_connection_manager which is the simplest filter we use to redirect traffic. The second important thing to observe is the source and destination ports. We are listening to the traffic at port 8080 and redirecting to port 1111. This is a simple example where both envoy proxy and application server are running on the same local machine, whereas this would not be the case in the real world and we will see more meaningful usage of cluster address. For now, let’s run and test the envoy proxy.
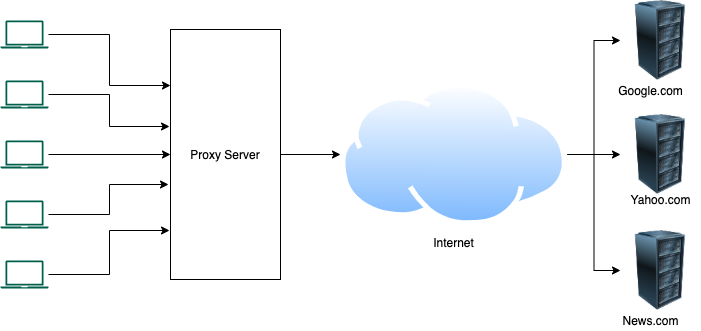
The reverse proxy pattern is a very common pattern used when we use a microservices-based design. Before understanding reverse proxy, it makes sense to spend a minute to understand what the term proxy means in terms of the Internet. Proxies are usually used by big organizations to control traffic. The image below helps us illustrate the use of the proxy layer.
Proxy Layer
In a normal scenario when a machine accesses a site like google.com, it will know that the traffic is coming from the A.B.C.D IP address. But if we introduce a proxy layer in between, the client machine for google changes from A.B.C.D IP to the Proxy machine. So google will not know about the actual client requesting data.
Use of Proxy layer gives organizations control on traffic in terms of
Anonymity
Caching
Logging usage
Block Sites
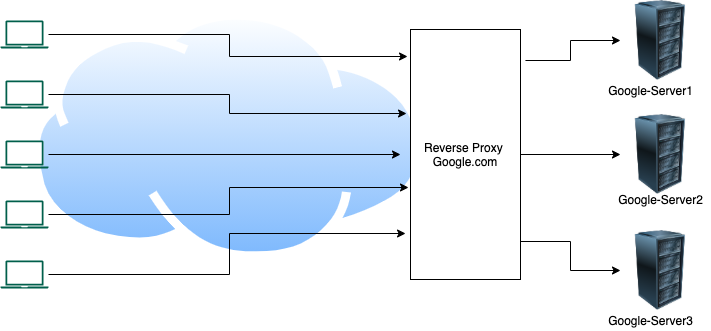
Coming to Reverse Proxy, as the name suggests, it reverses the effect of proxying. That is, instead of introducing the proxy layer at the client-side, we have the proxy layer at the server or provider side. Let us how the flow looks with help of the image below.
Reverse Proxy
As we can in the image above that in the case of reverse proxy, the proxy layer shields actual servers where services are implemented. For the external world, the reverse proxy server is the actual destination implementation, for the example shown above, anyone looking for google.com will hit the reverse proxy server say A.B.C.D IP address. But A.B.C.D is not the machine actually processing the requests. It receives the request and passes it on to a backend server which actually fulfills the request and returns the results back to the caller.
A reverse proxy server help achieve features like
Caching
Load Balancing (send same requests to any of the servers among a set)
Ingress (take multiple types of requests and choose the correct server)
Canary / Blue-Green deployments
The reverse proxy pattern can be extended to provide many more features like rate limiting, authentication/ authorization, TLS offloading, etc. Most advanced tools fall under the category of API Gateway. There is a thin line between Reverse proxy and API gateway and you can at times feel the terms being used interchangeably. The video below tries to demystify the line between API Proxy and API Gateway.
We often hear the phrase that data is the most important entity in the new world. The success of any product or company is dependent on the amount of data that can be acquired and processed for decision making. With such an emphasis on data, it was evident that the software industry explores additional options for storing data along with traditional RDBMS.
This does not mean Relational databases are not good enough, they are good for some of the use cases but do have their limitations. For example, a relational database can be difficult to scale (sharding is there but it has its own limitations), can be challenging to manipulate (try adding a new column to an existing table), or can be slow (complex join based queries).
No-SQL database is not just a single database, but more of an umbrella term covering a set of databases or in simple words a non-RDBMS database is termed as a no-SQL database. Let’s take a look at four broad categories in which no-SQL databases can be divided.
Key-Value database: Most simple form for storing data. As the name suggests data is stored in form of Key-Value pairing, think of it as a hashmap kind of data store. Data can easily grow exponentially as long as the keys being used are unique.
Example: Redis, Riak
Document-based database: This can be thought of as an extension to the key-value database. The values being stored are in form of a structured document. Metadata is provided so that each document is indexed and is searchable.
Example: MongoDB, CouchDB, CosmosDB
Column-based database: RDBMS stores data in form of row-based storage. In contrast, a column-based database stored the data in column-oriented storage. This gives an advantage for searching data based on columns easily and at the same time lets your data grow up to large levels by supporting the distribution of data. Further Read: https://en.wikipedia.org/wiki/Column-oriented_DBMS
Example: Cassandra, HBase
Graph-based database: An interesting set of data can be where each data node is linked to another node in some manner. For example, think of a social networking site, where each profile node can be linked to another node as a friend (or colleague). Graph-based databases provide inbuilt support for storing this kind of data.
Cloud computing or Cloud has become a term that is used very loosely now in the software industry. It is important that we understand what the cloud is. If we think of the cloud objectively, it is nothing but a set of services clubbed together and being offered by various cloud services providers. These services can be as simple as getting a Virtual Machine off the shelf, or onboarding a sophisticated complex machine-learning algorithm to process our data.
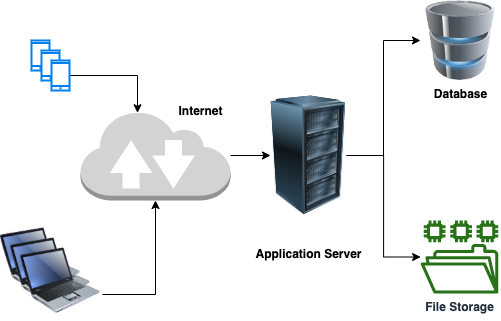
Let’s think of a very simple application. What all you need to deploy a simple application and make it available to end-users?
Deployment for a simple web application
The bare minimum services that one needs for an application to be deployed are server, database, and storage. We are not talking about scalability, security, API gateway services for now to keep it simple. If we go to any cloud platform we do get all these services in common umbrella service types of Compute, Storage, and Database.
Amazon Web Services
Compute: Compute is the most basic set of services provided by a cloud service provider. In simple words, this is where you will deploy your code and execute it. The simplest form of the compute service is Virtual machines. You can provision VMs from the cloud and deploy tools and services needed for your application to work. You deploy your application and expose it to the outside world.
Storage: Second most important thing that an application will need is storage. You need to store images, files, logs, etc. for your application to work fine. All cloud services provide us with different storage options. Customized according to user needs with respect to performance, security, redundancy, etc.
Database: Another set of services that are core to any application is a database. The database itself has gone through many interesting transitions in the last few years. From just Relational databases, we have now a set of no-SQL databases, which includes a column-based database, document-based database, graph-based database, key-value database, and so on. All major cloud service providers have good support for all the common databases and provide additional features like encryption, redundancy, etc off the shelf.
Other important services: Though we have talked about only Compute, Storage, and Database so far, the cloud platform provides many more services. Services related to Networking, Security, Machine Learning, IoT, etc. are available off the shelf from cloud service providers.
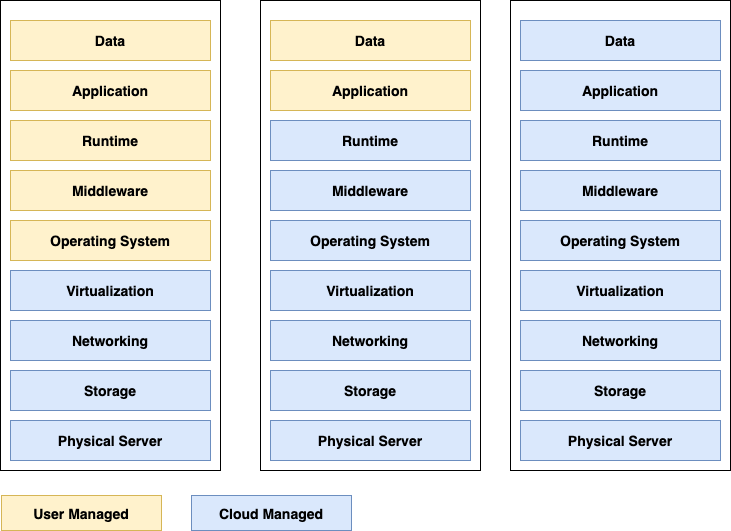
Most of the services provided by cloud platforms can be divided into three broad categories, namely, IaaS or Infrastructure as a Service, PaaS or Platform as a Service, and SaaS or Software as a Service. Let us take a look at these concepts one by one.
IaaS vs PaaS vs Saas
IaaS or Infrastructure as a Service, as the name suggests, are services where the cloud service provider is responsible for providing infrastructure requirements and the development team deploys any required software. A very simple use case is getting VMs from cloud service providers and deploying a service or application on that. In this case, the development team is responsible for installing any required tools or software on the VM and managing them.
PaaS or Platform as a Service reduces the responsibility of the development team and lets them focus more on the core task that is the development of applications and services. For example, Amazon provides Elastic Beanstalk service where one needs to deploy the code straightaway. No need to worry about the underlying hardware or setting up the runtime environment.
SaaS or Software as a Service, as the name suggests, provides a layer of abstraction on the actual software. When you are using a SaaS service you are not worried about the underlying complexity of how the hardware or OS or data is being managed. All you need to do is onboard to the service and start using it. For example, an email service provider like Gmail. when you create an account with Gmail, you are not worried about the fact that how the data is being processed or how the service will scale.
People who are in software development for more than a decade, understands the importance of change that has been brought by the cloud. Think of a scenario, where you a cool idea for a service or an application, you do a small POC and want to show it to your friends or colleagues. In pre-cloud era, you would need to buy some hardware, setup a static IP (which btw would cost you fortune), buy licenses for hardware and softwares, make sure you have proper power backups, and the list continuos. All this pain just for a test app, forget about a production level deployment.
Coming to today’s scenario, if I need to deploy an application and share a test link with my friends, all I need to do is to login into my favorite cloud platform, get a free tier VM, deploy my application and share the link. This would hardly take me 5 minutes, and mostly would be done free of cost (most cloud services have free tier support for these test scenarios).
The above mentioned is just a simple scenario where we are using a VM off the shelf from a cloud service provider. In reality, you have a plethora of services to choose from ranging from the compute to database to machine learning to IoT and whatnot. Cloud computing has really changed the way we use to imagine the software development process.